语音识别人工智能解决方案
背景介绍语音识别技术,也被称为自动语音识别(Automatic Speech Recognition ,ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。与说话人识别及说话人确认不同,后者尝试识别或确认发出语音的说话人而非其中所包含的词汇内容。
语音识别系统一般分训练和解码两阶段。训练,即通过大量标注的语音数据训练声学模型;解码,即通过声学模型和语言模型将训练集外的语音数据识别成文字,训练的声学模型好坏直接影响识别的精度。
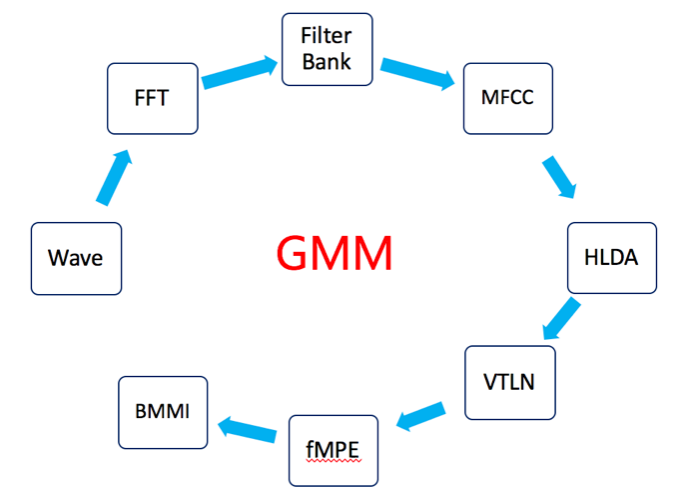
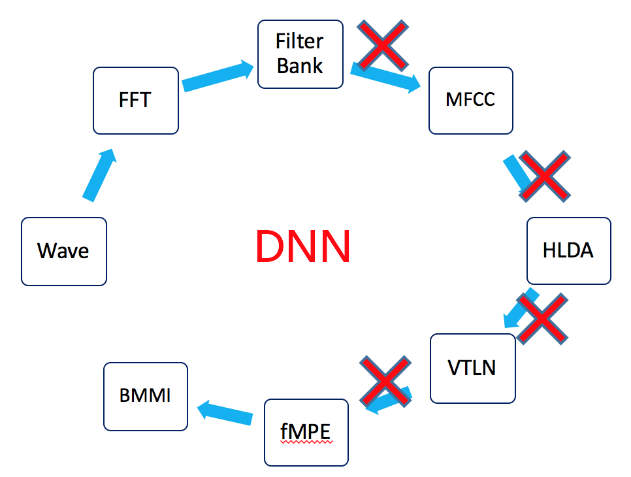
语音识别技术已经发展了几十年,直到2009年,Hinton把人工智能深度学习解决方案引入语音识别中,语音识别才取得了巨大突破。本质上是把传统的混合高斯模型(GMM)替换成了深度神经网络(DNN)模型,传统GMM提取语音特征(如左下图所示)经过多个过程,而DNN模型提取语音特征(如右下图所示)可以精简不少工作,不需要对语音数据分布进行假设,不需要切分成stream来分段拟合;DNN的输入可以将相邻语音帧拼接成包含时序结构信息的矢量,在帧层次利用更多的上下文信息,相对识别错误率一下降低20%多,这个改进幅度超过了过去很多年的总和。这里的关键是把原来模型中通过GMM建模的手工特征换成了通过DNN进行更加复杂的特征学习。在此之后,在深度学习框架下,人们还在不断利用更好的模型,如RNN,LSTM和更多的训练数据进一步改进结果,深度学习使得语音识别的准确率能达到99%,足以在实验测试以外的实际场景中应用,并且被广泛商用。
解决方案介绍语音识别技术已经发展了几十年,直到2009年,Hinton把人工智能深度学习解决方案引入语音识别中,语音识别才 取得了巨大突破。本质上是把传统的混合高斯模型(GMM)替换成了深度神经网络(DNN)模型,传统GMM提取语音 特征(如左下图所示)经过多个过程,而DNN模型提取语音特征(如右下图所示)可以精简不少工作,不需要对语音数据分布进行假设,不需要切分成stream来分段拟合;DNN的输入可以将相邻语音帧拼接成包含时序结构信息的矢量,在帧层次利用更多的上下文信息,相对识别错误率一下降低20%多,这个改进幅度超过了过去很多年的总和。这里的关键是 把原来模型中通过GMM建模的手工特征换成了通过DNN进行更加复杂的特征学习。在此之后,在深度学习框架下,人 们还在不断利用更好的模型,如RNN,LSTM和更多的训练数据进一步改进结果,深度学习使得语音识别的准确率能达到 99%,足以在实验测试以外的实际场景中应用,并且被广泛商用。目前所有的商用语音识别算法没有一个不是基于深度学 习的,采用深度学习进行语音识别整个处理过程如下图所示。









